Emily Milius
Suggested Citation
The voice holds immense power and is one of the most critical aspects of listener perception in popular song. In her book, A Blaze of Light in Every Word (2020), Victoria Malawey delivers a concrete methodology for analyzing the singing voice in popular music that synthesizes the wealth of vocal scholarship across multiple disciplines. Her groundbreaking methodology, which draws from vocal science, music theory, and performance, gender, and embodiment studies, as well as the analytical model presented in her 2011 article, aims “to provide a systematic approach for discussing the wide-ranging and often ineffable aspects of vocal delivery in popular music recordings, with the goal to aid and enhance musical analysis” (2020, 2). In Chapters 2–5 of this five-chapter monograph, she employs this methodology to examine covers of popular songs from the last forty years. Ironically, it seems as though Malawey’s own voice can get somewhat lost as she engages with such a vast array of scholarship in her literature reviews and analyses throughout each of the book’s five chapters. In short, Malawey’s conclusions can sometimes be veiled within her references. That being said, no other scholar has done such extensive work to harmonize these various forms of dense research on the voice, and this work will no doubt be an imperative and indispensable resource for anyone who studies the singing voice, especially in popular song.
Malawey opens the introduction (Chapter 1) with a discussion of Jimmy Fallon and Jamie Foxx comically imitating iconic singers during the “Wheel of Musical Impressions” on The Tonight Show. In this example, Fallon mimics Barry Gibb (with the song “I Love You, You Love Me” from Barney and Friends) and Bruce Springsteen (singing America’s Funniest Home Videos’s theme song). Foxx performs impressions of singers identifying with different races and genders: Mick Jagger (singing “Hakuna Matata”), John Legend (performing the Toys “R” Us jingle), and Jennifer Hudson (with a rendition of “On Top of Spaghetti”). Through this example, Malawey shows how changes in vocal pitch, register, phrasing, and quality of sound create successful illusions of different performers and their “seemingly ‘unique’” singing voices (2). In doing so, Malawey draws from Nina Sun Eidsheim (2019) and others (Neumark 2010; Eidsheim 2012, 2015; Weidman 2014;) to demonstrate the performative and malleable qualities of vocal timbre both in the Tonight Show example and other similar cases. Throughout this and other discussions about how aspects of the voice can be understood to be representative of identity, Malawey is clear to point out that these are ideas and assumptions made by those listening to the song and being created (consciously or not) by performers. She subsequently draws the conclusion that markers of identity are not innately bound inside the voice itself, and asserts that “we must not assume certain markers of vocality are essential or biological features of any individual or group identity” (24). Additionally, she highlights that the gendered discussions of voice obviously leave out not only transgender, non-binary, and genderqueer singers, but also cisgender performers whose voices do not fit within normative ideas about the voice.
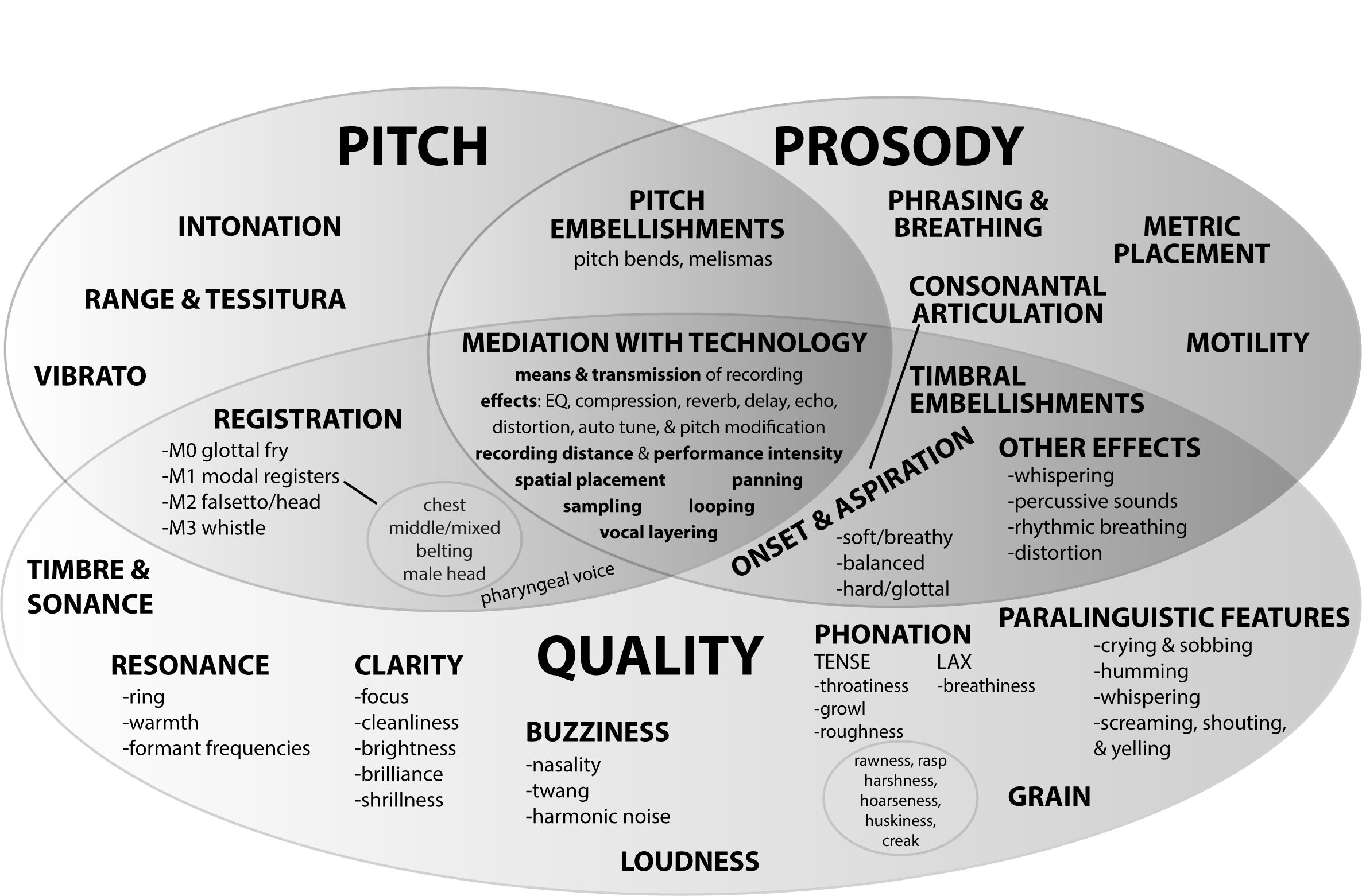
To outline her analytic methodology, Malawey provides a helpful Venn diagram (Example 1) that illustrates how different aspects of the voice—pitch, prosody, and quality, which are the subjects of Chapters 2–4, respectively—interact with one another, and are mediated with technology (the topic of Chapter 5). In this diagram, Malawey thoroughly depicts the various components that make up pitch, quality, and prosody, as well as the ways in which they overlap with one another, such as registration, timbral and pitch embellishments, and mediation with technology. Beyond showing the combination of elements that play into understanding the voice, her chart could also be used as an excellent resource for anyone trying to understand how these elements can be assessed, both separately and together. It would therefore serve as a useful system for undertaking a dynamic analysis of the popular singing voice (or possibly any singing voice, for that matter). In the chapters following, she explains in greater detail pitch, prose, and quality—the largest circles in the Venn diagram—and digs deeper into the smaller aspects that characterize them.
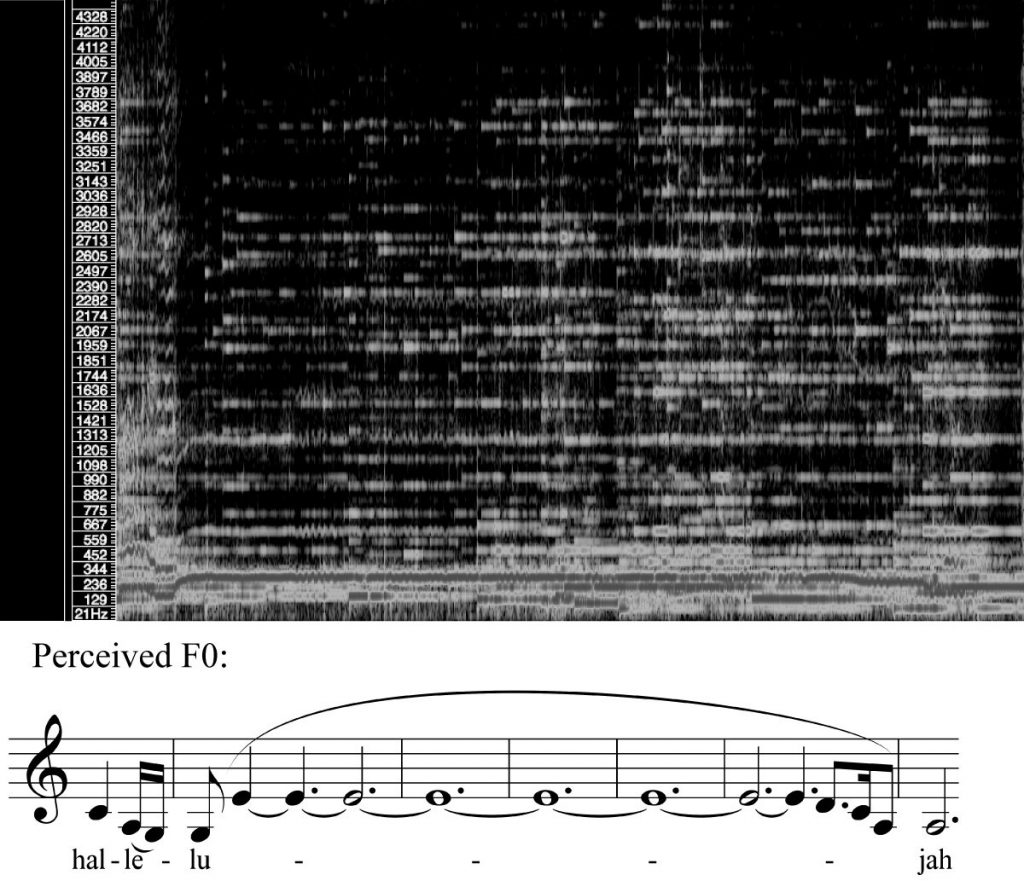
In Chapter 2, Malawey discusses pitch and its relationship with the voice, which has the ability to convey meanings in ways that instruments cannot. Malawey’s description of pitch considers range and tessitura, intonation, vibrato, and register. To show how these elements can be heard and analyzed by listeners as markers of gender identity and age, she compares covers of Leonard Cohen’s “Hallelujah” (1984), including those by Jeff Buckley (1994), Rufus Wainwright (2001), k.d. lang (2004), Imogen Heap (2006), Alexandra Burke (2008), and Kate McKinnon (2016). Using these aspects of pitch, she argues that each of these performers brings their own meanings into this song based on their vocal expressions. These various meanings in turn each add something to “the larger narrative that unfolds over the course of this song’s three-decade history” (57). Malawey’s analyses pair musical transcriptions with spectrograms to illustrate how range, intonation, vibrato, and register are used across these different performances. An example of two of her visualizations can be seen in Examples 2 and 3. In Example 2, the spectrogram displays an example of k.d. lang’s head voice, in which the darker space at the top shows less overtone activity at the upper end of the series. Even less activity (and more dark space) is shown above the fundamental in a clip of Buckley’s falsetto voice, as can be seen in Example 3.

By comparing these performances, Malawey convincingly demonstrates “how aspects of pitch relate to the constructions and perception of gender identity and age” and the creation of different narratives (32; italics added). For example, she notes that Buckley’s ability to easily navigate registration with such a large range (especially in his higher registers) conveys ethereality and sexuality, with the high voice possibly allowing for a queer interpretation. In opposition, lang’s performance includes a stark contrast between registers, as well as the use of vocal fry, making it more emotionally expressive. These interpretations relate to gendered stereotypes (e.g., men’s sexual prowess and emotional detachment and women’s lack of emotional control) as well as age assumptions (e.g., sexuality implies biological maturity), which listeners associate with the performers through their voices. Using excerpts from the various covers of “Hallelujah,” she shows how each performer uses aspects of pitch and register in particular ways, such as Buckley’s switches from chest, to head, to falsetto voices and the use of both chest and head voice in lang’s and Burke’s recordings. More specifically, she observes that the song’s lyrical and expressive meaning varies through these renditions, ranging from a religious or spiritual hymn, like Cohen’s or Burke’s, to an explicitly sexual narrative, like Buckley’s.
While Malawey touches upon aspects of range and tessitura, intonation, and vibrato, she devotes most of the second chapter to discussing register and listeners’ assumptions about the identity of a singer based on their voice. Malawey draws from multiple types of vocal scholarship—including vocal science (e.g., Callaghan 2000; Henrich 2006), linguistics (e.g., Kreiman and Sidtis 2011), vocal pedagogy (e.g., McKinney 1982; Morris and Chapman 2006; Malde et al. 2009), and voice studies in musicology (e.g., Wise 2007, Feldman 2015)—to distinguish how the thickness and connection of the vocal folds create four distinct vocal registers: M0/vocal fry, M1/modal voice (which encompasses multiple forms of vocality), M2/head voice and falsetto, and M3/whistle tone.1 Additionally, she explains the problems associated with essentializing gendered (or even sexed) distinctions based on biological factors connected to vocal registers, citing both vocal and feminist scholarship. She specifies that even when discussing sex, “biological” factors of the vocal tract have been societally constructed and not proven as essential fact (60–62). Malawey draws upon scholarship by Suzanne Cusick (1999), Susan McClary (2013), Nina Sun Eidsheim (2015), and others, as well as her own analyses of the covers of “Hallelujah,” to problematize listeners’ automatic gender assumptions based on vocal sounds, particularly in regard to register, amount of breathiness, and musical genre. She maintains that these aspects of pitch not only play into listeners’ assumptions about genre and gender, but that they also should be reconsidered to include more expansive ideas about gender identity.
Malawey continues with a similar organization and methodology to examine prosody in Chapter 3. She effectively provides “a method and language for describing the characteristics of vocal prosody that have previously been difficult to address” (93). She breaks prosody—or “the pacing and flow of delivery”—into five components: phrasing, metric placement, motility (or a singer’s “capacity for agility”), embellishment, and consonantal articulation (69–70, 79). After examining these components, Malawey makes three levels of what she calls “prosodic profiles” (70): broad (or genre-specific), middle (or artist-specific), and local (or individual performance-specific). Similar to the previous chapter, cover versions of a single song form the basis for her analyses—in this case, Justin Timberlake’s “Cry Me a River” (2002)—allowing her to propose a way to analyze vocal flow across multiple genres and show how speech and song integrate in vocal prosody to portray meaning within song texts. In addition to Timberlake’s original version, which represents R&B-infused pop, Malawey explores versions by Glen Hansard (2003, folk-rock), Ten Masked Men (2003, death metal), and The Cliks (2006, indie rock). Through her investigations of these covers, Malawey discovers individualized uses of inter- and intra-phrase connectivity, syncopation and word stress, ease of movement, and accent of consonants that distinguish both individual performances and larger genre categories from one another. By examining the ways that text is organized and stressed in these songs, Malawey is able to demonstrate how voice and lyrics not only intertwine in portraying meaning, but also in the production of sound more generally.
Vocal quality, one of the most important factors influencing the consumption of recorded popular music today, is the subject of Chapter 4. Here, Malawey expounds upon different features of vocal quality, including timbre and sonance, phonation, onset and aspiration, resonance, clarity, buzziness, vocal effects and paralinguistic features (such as crying or screaming), and loudness. Drawing from scholarship by Fales (2002; 2005), Moore (2012), Heidemann (2016), Wallmark (2014), and others, Malawey develops a strong methodology for analyzing vocal timbres that focuses on the physical production, acoustic information, and listener perception (including embodiment) of vocal quality. When applying her methodology throughout this chapter, she points out the strong correlation between listeners’ associations of timbre and individuality. Furthermore, she provides reasoning for the ways in which aspects of sonance “may help us better describe and specify the physiological, acoustic, and perceived qualitative aspects that we associate with various emotive effects in popular music” (125). To illustrate the ineffability of vocal quality, she examines assorted recordings of The Cliks’ lead singer, Lucas Silveira, both pre- and post-testosterone hormone therapy (pre-T/post-T) to offer perspectives on the ways that the vocal changes he experienced through transition affect how listeners associate his voice with his gender and vice versa.
Malawey continues to use both musical transcription and spectrograms to portray her analyses in the fourth chapter. Following Kate Heidemann (2016), Malawey contends that by showing acoustic information, spectrograms can be helpful in deciphering this information into perceptual discourse, particularly when considering the embodied aspects of timbral production. For example, in Malawey’s examination of the original and two cover versions of “Bad Romance”—Lady Gaga (2009, original version), Lucas Silveira and The Cliks (2009, pre-T and 2011, post-T, respectively)—she uses spectrographic analysis to illustrate differences in the perceived clarity in the artists’ voices, specifically the varying amounts of overtones in each recording. Malawey notes that “Silveira’s 2009 version features the fewest prominent overtones of all three versions during this passage, which acoustically represents the relative clarity listeners might perceive” (116). In brief, Malawey’s analysis of a transgender singer’s timbre not only gives visibility to transgender singers and the transgender community writ large, but also provides commentary on the performance and perception of gendered aspects of the voice.
In Chapter 5, Malawey focuses on the voice’s mediation with technology, emphasizing “the fiction of the natural” (127–130). After discussing the idea of a voice being either “wet” (perceived to be manipulated by technology in one or more ways) or “dry” (perceived to be natural), she states,
all recorded sounds—no matter how seemingly dry—are indeed technologically mediated: a sound source is first mediated by the microphone used to record it, then by the amplifier and audio interface that sends the signal to a digital audio workstation, which is then mixed as a track into the recording … which is then bounced to a digital audio file such as a .wav or .mp3, then transmitted to a listener’s speakers or headphones. (129)
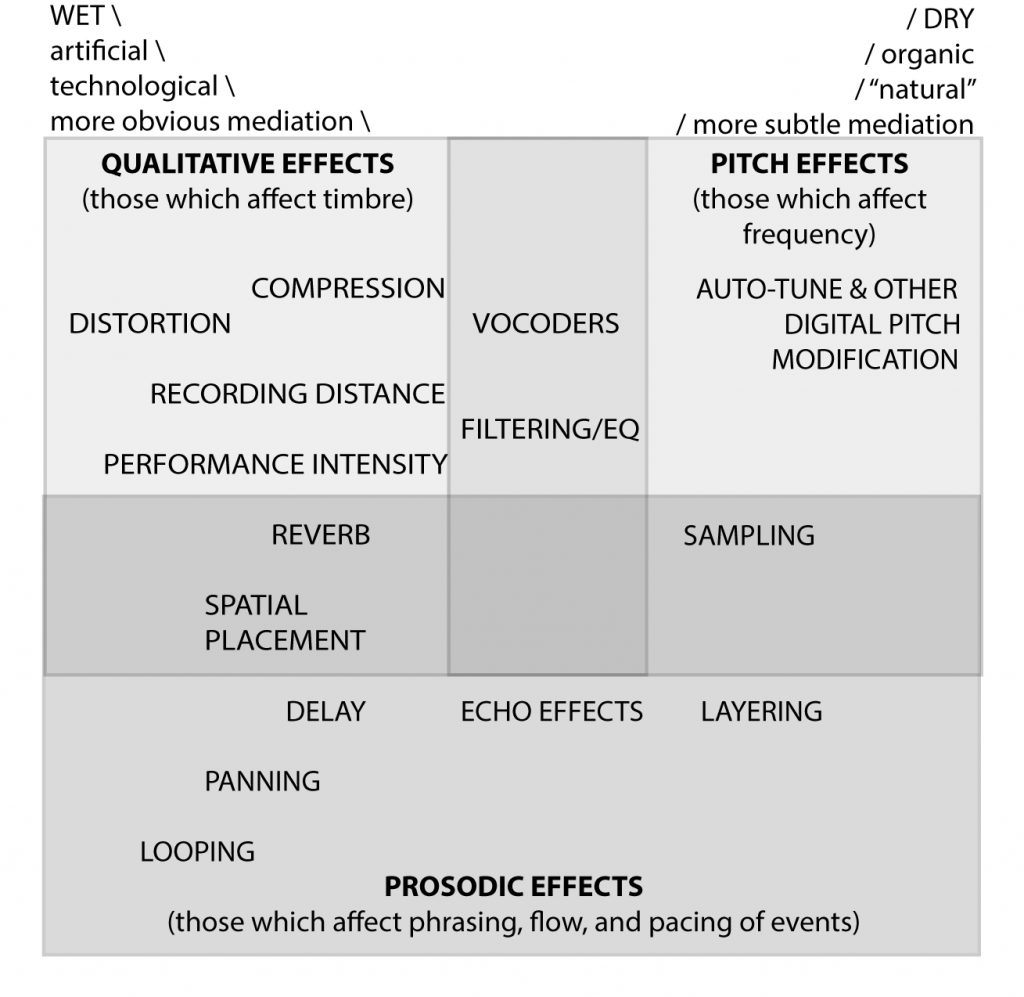
She goes on to problematize the “concept of naturalness” (130) and asserts that many aspects of identity, which are assumed to be innate—such as gender and race—are actually unnatural constructions created by many societies. Malawey describes many different ways in which the voice can be edited with technology, including layering, multi-tracking, looping, digital pitch modulation, equalization and filtering, distortion, spatial placement, microphone placement, performance intensity, reverberation, delay effects, and compression. Additionally, she provides another helpful diagram depicting a continuum of these effects from “wet” to “dry,” which can be seen in Example 4.
To exhibit how these various effects can affect listener perception and vocal analysis, Malawey supplements her explanations with another set of cover song analyses, this time using two songs originally performed by Björk. In the first selection, “Hunter” (1997), Malawey juxtaposes Björk’s performance, which she describes as alternating between seemingly dry and wet vocals, with Kaitlyn ni Donovan’s 2004 cover. Donovan’s cover, Malawey explains, uses far less technological mediation than Björk’s recording. For Malawey, Björk’s “marked contrasts in vocal processing” allow for various interpretations, while Donovan’s “creates a more straightforward storytelling experience” (143). For the second song, “Who Is It,” Malawey compares Bon Iver’s 2012 cover with Björk’s original recording (2004). Malawey concludes that “technological processes may become fused with musical content, form, and an artist’s vocality to such a degree that they define…sound and musical identity” (146). Through the analyses in this chapter, Malawey provides both a reason and methodology for considering the technological aspects of the voice as part of the sound and musical narrative.
Malawey explores issues related to the reproduction of emotive quality and authenticity in musical covers in Chapter 6, titled “Synthesis, or Why Covers of Elliott Smith Songs Don’t Work.” Here, she argues that “the same emotive quality becomes difficult if not impossible to convey through other singing voices” in subsequent musical covers (147). Moreover, she suggests that the quality of both the singing voice and emotion in the original and cover versions of a song affects listeners’ perception of an artist’s authenticity. She examines three songs by Elliott Smith—“Between the Bars” (1997), “Twilight” (2004), and “Roman Candle” (1994)—and their cover versions by Seth Avett and Jessica Lea Mayfield (2015) using the tools and methodologies from Chapters 2–5 to reinforce these points. For Malawey, the Avett and Mayfield covers “do not work” based on their differences in pitch, prosody, quality, and technological mediation. In short, “no one else can sound, and therefore emote, just like Elliot Smith” (176). While Malawey makes a compelling argument about why the variances in vocal aspects create versions that may or may not “work,” this chapter’s title carries the implication that covers of Elliot Smith’s songs are “wrong” or “bad,” even though that does not seem to be what Malawey is saying. It is clear that the variances she points out are important and create different meanings in the original and subsequent covers; they make unique recordings that are independent from the original in ways that cannot be exactly the same, but that are not necessarily “incorrect” or “poor.” That being said, Malawey’s assessment that covers cannot recreate the original performer’s expression and vocal quality is convincing and perceptible as a listener. Throughout this final chapter, she provides multiple examples of her methodology in action that serve as persuasive analyses. In doing so, she emphasizes the usefulness of these analytic tactics in assessing authenticity and meaning, among other things, in recordings of popular song.
In conclusion, Malawey presents an extensive literature review and develops a cutting-edge methodology for anyone who seeks to analyze, or just learn more about, the popular singing voice. Malawey’s scholarship in A Blaze of Light in Every Word not only dissects and explains the many aspects that comprise the voice, but also proposes ways to perceive and discuss how these aspects work together to create vocal expression in popular song. By using cover songs as her main source of study, Malawey is able to point out distinct differences in songs which are, on the surface, the same. In the process, Malawey convincingly showcases the immense power the voice holds, most especially in how listeners perceive emotional expression, authenticity, and meaning in songs containing the same basic lyrical, melodic, formal, and rhythmic content.
Emily Milius
She/Her
PhD Student in Music Theory
Graduate Teaching Employee of Music Theory
The University of Oregon
Secretary, SMT Popular Music Interest Group
Web Manager, Women’s Song Forum
emilius@uoregon.edu
References
Callaghan, Jean. 2000. Singing and Voice Science. San Diego: Singular Publishing Group.
Cox, Arnie. 2016 Music and Embodied Cognition: Listening, Moving, Feeling, and Thinking. Bloomington: Indiana University Press.
Eidsheim, Nina Sun. 2012. “Voice as Action: Toward a Model for Analyzing the Dynamic Construction of Racialized Voice.” Current Musicology 93: 9–32.
———. 2015. “Race and the aesthetics of vocal timbre.” In Rethinking Difference in Music Scholarship, edited by Olivia Bloechl, Melanie Lowe, and Jeffrey Kallberg, 338–65. Cambridge: Cambridge University Press.
———. 2019. The Race of Sound: Listening, Timbre and Vocality in African American Music. Durham: Duke University Press.
Fales, Cornelia. 2002. “The Paradox of Timbre.” Ethnomusicology 46 (1): 56–95.
———. 2005. “Short-Circuiting Perceptual Systems: Timbre in Ambient and Techno Music.” In Wired for Sound: Engineering and Technologies in Sonic Cultures, edited by Paul D. Greene and Thomas Porcello, 156–80. Middletown: Wesleyan University Press.
Feldman, Martha. 2015. The Castrato: Reflections on Natures and Kinds. Oakland: University of California Press.
Heidemann, Kate. 2016. “A System for Describing Vocal Timbre in Popular Song.” Music Theory Online 22 (1). https://www.mtosmt.org/issues/mto.16.22.1/mto.16.22.1.heidemann.html. Accessed January 20, 2022.
Henrich, Nathalie. 2006. “Mirroring the voice from Garcia to the present day: Some insights into singing voice registers.” Logopedics Phoniatrics Vocology 31 (1): 3–14.
Kreiman, Jody and Diana Sidtis. 2011. Foundations of Voice Studies: An Interdisciplinary Approach to Voice Production and Perception. Hoboken: Wiley-Blackwell.
Malde, Melissa, MaryJean Allen, and Kurt Alexander Zeller. 2009. What Every Singer Needs to Know about the Body. San Diego: Plural Publishing.
Malawey, Victoria. 2011. “An Analytic Model for Examining Cover Songs and Their Sources.” In Pop-Culture Pedagogy in the Music Classroom: Teaching Tools from American Idol to YouTube, edited by Nicole Biamonte, 203–32. Lanham: Scarecrow Press.
———. 2020. A Blaze of Light in Every Word: Analyzing the Popular Singing Voice. New York: Oxford University Press.
McKinney, James. 1982. The Diagnosis and Correction of Vocal Faults: A Manual for Teachers of Singing and Choir Directors. Nashville: Boardman Press.
Moore, Allan. 2012. Song Means: Analysing and Interpreting Recorded Popular Song. Burlington: Ashgate.
Morris, Ron, and Janice Chapman. 2006. “Articulation.” In Singing and Teaching Singing, edited by Janice Chapman, 97–128. San Diego: Plural Publishing.
Neumark, Norie. 2010. “Doing Things with Voices: Performativity and Voice.” In Voice: Vocal Aesthetics in Digital Arts and Media, edited by Norie Neumark, Ross Gibson, and Theo van Leeuwen, 95–118. Cambridge: MIT Press.
Wallmark, Zachary. 2014. “Appraising Timbre: Embodiment and Affect at the Threshold of Music and Noise.” PhD diss., UCLA.
Weidman, Amanda. 2014. “Anthropology and Voice.” Annual Review of Anthropology 43: 37–51.
Wise, Timothy. 2007. “Yodel Species: A Typology of Falsetto Effects in Popular Music Vocal Styles.” Radical Musicology 2. http://www.radical-musicology.org.uk/2007/Wise.htm. Accessed January 17, 2022.